ip
1 | 查看出口IP(公网IP) |
gnuplot图形化
1 | 图形化 |
xargs
1 | xargs捕获while;do输出,-I {}参数替换,bash -c “cmd string”执行命令 |
端口占用查看
windows
1 | # 查看端口 |
linux
1 | 列出所有端口的情况 |
1 | 查看出口IP(公网IP) |
1 | 图形化 |
1 | xargs捕获while;do输出,-I {}参数替换,bash -c “cmd string”执行命令 |
1 | # 查看端口 |
1 | 列出所有端口的情况 |
1 | pip install requests # http请求 |
给Python添加默认路径在Python3X\Lib\site-packages下添加一个路径文件,如mypath.pth,必须以.pth为后缀。文件中直接写上你要加入的模块文件所在的目录名称,可以添加多个目录。
1.7.4版本ride使用cmd正常显示中文,使用RIDE执行用例时控制台和日志乱码
1 | 修改Lib\site-packages\robotide\contrib\testrunner\testrunnerplugin.py def _AppendText if PY2 else下的 |
1 | 安装相关依赖 |
1、尽可能早的找出系统中的Bug;
2、避免软件开发过程中缺陷的出现;
3、衡量软件的品质,保证系统的质量;
4、关注用户的需求,并保证系统符合用户需求。
总的目标是:确保软件的质量。
可行性分析、需求分析、概要设计、详细设计、编码、单元测试、集成测试、系统测试、验收测试
按测试策略分类:1、静态与动态测试2、黑盒与白盒测试 3、手工和自动测试 4、冒烟测试 5、回归测试;
按测试阶段分类:单元测试、集成测试、系统测试;
其他常见测试方法:1、功能测试 2、性能测试 3、压力测试 4、负载测试 5、易用性测试 6、安装测试 7、界面测试 8、配置测试 9、文档测试 10、兼容性测试 11、安全性测试 12、恢复测试
一般用来确认软件功能的正确性和可操作性,目的是检测软件的各个功能是否能得以实现,把被测试的程序当作一个黑盒,不考虑其内部结构,在知道该程序的输入和输出之间的关系或程序功能的情况下,依靠软件规格说明书来确定测试用例和推断测试结果的正确性。
优点:比较简单,不需要了解程序内部的代码及实现;与软件的内部实现无关; 从用户角度出发,能很容易的知道用户会用到哪些功能,会遇到哪些问题;基于软件开发文档,所以也能知道软件实现了文档中的哪些功能;在做软件自动化测试时较为方便。
缺点:不可能覆盖所有的代码,覆盖率较低,大概只能达到总代码量的30%;自动化测试的复用性较低。
1)等价类划分: 等价类是指某个输入域的子集合.在该子集合中,各个输入数据对于揭露程序中的错误都是等效的.并合理地假定:测试某等价类的代表值就等于对这一类其它值的测试.因此,可以把全部输入数据合理划分为若干等价类,在每一个等价类中取一个数据作为测试的输入条件,就可以用少量代表性的测试数据.取得较好的测试结果.等价类划分可有两种不同的情况:有效等价类和无效等价类.
2)边界值分析法:是对等价类划分方法的补充。测试工作经验告诉我,大量的错误是发生在输入或输出范围的边界上,而不是发生在输入输出范围的内部.因此针对各种边界情况设计测试用例,可以查出更多的错误.
使用边界值分析方法设计测试用例,首先应确定边界情况.通常输入和输出等价类的边界,就是应着重测试的边界情况.应当选取正好等于,刚刚大于或刚刚小于边界的值作为测试数据,而不是选取等价类中的典型值或任意值作为测试数据.
3)错误猜测法:基于经验和直觉推测程序中所有可能存在的各种错误, 从而有针对性的设计测试用例的方法.
错误推测方法的基本思想: 列举出程序中所有可能有的错误和容易发生错误的特殊情况,根据他们选择测试用例. 例如, 在单元测试时曾列出的许多在模块中常见的错误. 以前产品测试中曾经发现的错误等, 这些就是经验的总结. 还有, 输入数据和输出数据为0的情况. 输入表格为空格或输入表格只有一行. 这些都是容易发生错误的情况. 可选择这些情况下的例子作为测试用例.
4)因果图方法:前面介绍的等价类划分方法和边界值分析方法,都是着重考虑输入条件,但未考虑输入条件之间的联系, 相互组合等. 考虑输入条件之间的相互组合,可能会产生一些新的情况. 但要检查输入条件的组合不是一件容易的事情, 即使把所有输入条件划分成等价类,他们之间的组合情况也相当多. 因此必须考虑采用一种适合于描述对于多种条件的组合,相应产生多个动作的形式来考虑设计测试用例. 这就需要利用因果图(逻辑模型). 因果图方法最终生成的就是判定表. 它适合于检查程序输入条件的各种组合情况.
5)正交表分析法:可能因为大量的参数的组合而引起测试用例数量上的激增,同时,这些测试用例并没有明显的优先级上的差距,而测试人员又无法完成这么多数量的测试,就可以通过正交表来进行缩减一些用例,从而达到尽量少的用例覆盖尽量大的范围的可能性。
6)场景分析方法:指根据用户场景来模拟用户的操作步骤,这个比较类似因果图,但是可能执行的深度和可行性更好。
7)状态图法:通过输入条件和系统需求说明得到被测系统的所有状态,通过输入条件和状态得出输出条件;通过输入条件、输出条件和状态得出被测系统的测试用例。
8)大纲法:大纲法是一种着眼于需求的方法,为了列出各种测试条件,就将需求转换为大纲的形式。大纲表示为树状结构,在根和每个叶子结点之间存在唯一的路径。大纲中的每条路径定义了一个特定的输入条件集合,用于定义测试用例。树中叶子的数目或大纲中的路径给出了测试所有功能所需测试用例的大致数量。
根据软件内部的逻辑结构分析来进行测试,是基于代码的测试,测试人员通过阅读程序代码或者通过使用开发工具中的单步调试来判断软件的质量,一般白盒测试由项目经理在程序员开发中来实现。
优点:帮助软件测试人员增大代码的覆盖率,提高代码的质量,发现代码中隐 藏的问题。
缺点:程序运行会有很多不同的路径,不可能测试所有的运行路径;测试基于代码,只能测试开发人员做的对不对,而不能知道设计的正确与否,可能会漏掉一些功能需求;系统庞大时,测试开销会非常大。
静态测试是不运行程序本身而寻找程序代码中可能存在的错误或评估程序代码的过程。
动态测试是实际运行被测程序,输入相应的测试实例,检查运行结果与预期结果的差异,判定执行结果是否符合要求,从而检验程序的正确性、可靠性和有效性,并分析系统运行效率和健壮性等性能。
α测试是由一个用户在开发环境下进行的测试,也可以是公司内部的用户在模拟实际操作环境下进行的受控测试,Alpha测试不能由程序员或测试员完成。
β测试是软件的多个用户在一个或多个用户的实际使用环境下进行的测试。开发者通常不在测试现场,Beta测试不能由程序员或测试员完成。
单元测试:单元测试是针对软件设计的最小单位––程序模块甚至代码段进行正确性检验的测试工作,通常由开发人员进行。
集成测试:集成测试是将模块按照设计要求组装起来进行测试,主要目的是发现与接口有关的问题。由于在产品提交到测试部门前,产品开发小组都要进行联合调试,因此在大部分企业中集成测试是由开发人员来完成的。
系统测试:系统测试是在集成测试通过后进行的,目的是充分运行系统,验证各子系统是否都能正常工作并完成设计的要求。它主要由测试部门进行,是测试部门最大最重要的一个测试,对产品的质量有重大的影响。
验收测试:验收测试以需求阶段的《需求规格说明书》为验收标准,测试时要求模拟实际用户的运行环境。对于实际项目可以和客户共同进行,对于产品来说就是最后一次的系统测试。测试内容为对功能模块的全面测试,尤其要进行文档测试。
代码覆盖率也被⽤于自动化测试和⼿手测试,来度量测试是否全面的指标之⼀,应用覆盖率的思想增强测试用例的设计
1 | # 被测试函数 |
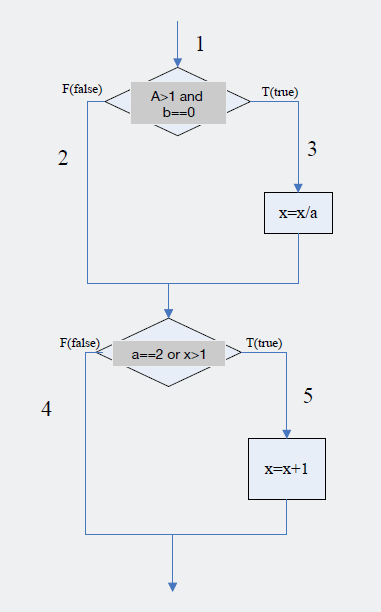
语句覆盖:运行测试用例的过程被击中的代码行即称为被覆盖的语句
1 | • 测试用例: |
条件覆盖:每一个判断覆盖语句中,每个可能的子条件或者合并条件都覆盖到
1 | • 测试用例:if (a > 1 and b == 0) |
路径覆盖:每一个可能的路径都覆盖
1 | • 测试用例: |
1 | 1. Seconds |
| 字段名 | 允许的值 | 允许的特殊字符 |
|---|---|---|
| 秒 | 0-59 | , - * / |
| 分 | 0-59 | , - * / |
| 小时 | 0-23 | , - * / |
| 日 | 1-31 | , - * ? / L W C |
| 月 | 1-12 or JAN-DEC | , - * / |
| 周几 | 1-7 or SUN-SAT | , - * ? / L C # |
| 年 (可选字段) | empty, 1970-2099 | , - * / |
1 | “?”字符:表示不确定的值 |
1 | 每隔5秒执行一次:*/5 * * * * ? |
1 | # Content-Type |
1 | access_ token接口将返回token放到变量中,并加断言 |
功能划分要简单清晰,一个测试用例只检查一个功能模块
测试用例的划分也要单一,一个测试用例只检查功能点的一种情况
测试用例要有简单的目的描述,要有明确的执行前提,包括环境,场景,数据,要有明确的测试数据
一般设计步骤
根据设计规格得出基本测试用例
1.补充边界值测试用例
2.补充错误猜测测试用例
3.补充异常测试用例
4.补充性能测试用例
是测试系统组件间接口的一种测试。
接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。
测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。
测试沟通能力
输入不同正确组合,验证返回正确(不同的响应状态码),逻辑正确,精度正确。
依赖有无,正确,其他,时间
空,不符合需求,功能不符合(参数个数,类型,缺失,左右边界,上下溢出,优先级,逻辑,文件各种问题)
输入的内容对域,对访问控制,权限,数据库sql注入
把软件看成一个黑盒子,不考虑内部结构,只考虑输入和输出,测试功能和ui界面。
将无限的测试变成有限的测试
大多用于输入框中的测试
有效等价类: 一条用例尽量覆盖有效规则
无效等价类:一条用例只能出现一次无效规则
适用对象:输入框,页面上的多个输入框不存在逻辑关系
缺点:没有关注到边界的问题,没有关注到输入框的逻辑关系
在任何用例中都必须用到的方法
边界值 :上点 离点 内点 一般配合等价类使用
能帮助我们在原有用例的基础上追加补充一些用例
输入条件需要考虑组合情况
参数之间存在逻辑关系,不同逻辑组合会输出不同结果 参数之间存在约束关系,输出结果不确定
判定表: 多条输入 多条输出 输入和输出之间存在逻辑关系
具体做法:条件桩 条件的组合(二进制)动作桩 动作项 适当的项目合并(注意不要合并成漏项)
参数配置类的测试
多个选项,都是正值,没有逻辑关系,因子的值两两相交一次(两个因子的值在一个用例中出现一次)利用正交工具
业务流程清晰的系统
基本流和备选流,一般基本流为正常的测试。测试结果为成功的测试,备选流为异常的情况测试
对于有状态迁移和逻辑功能路径组合的情况
对照程序逻辑,检查已设计出的测试用例逻辑覆盖度,如果没有达到要求的覆盖标准,应再补充足够的测试用例。
测试程序的内部结构和接口
语句覆盖,判定覆盖,条件覆盖,判定条件覆盖,条件组合覆盖,路径覆盖
1 | svn co http://路径(目录或文件的全路径) [本地目录全路径] --username 用户名 --password 密码 |
1 | svn export [-r 版本号] http://路径(目录或文件的全路径) [本地目录全路径] --username 用户名 |
1 | svn add 文件名 |
1 | svn commit -m “提交备注信息文本“ [-N] [--no-unlock] 文件名 |
1 | svn update |
1 | svn delete svn://路径(目录或文件的全路径) -m “删除备注信息文本” |
1 | svn lock -m “加锁备注信息文本“ [--force] 文件名 |
1 | svn diff 文件名 |
1 | svn st 目录路径/名 |
1 | svn log 文件名 |
1 | svn info 文件名 |
1 | svn help # 全部功能选项 |
1 | svn list svn://路径(目录或文件的全路径) |
1 | svn mkdir 目录名 |
1 | svn revert [--recursive] 文件名 |
1 | svn switch http://目录全路径 本地目录全路径 |
1 | svn resolved [本地目录全路径] |
1 | svn cat http://文件全路径 |
1 | svn copy branchAbranchB -m "make B branch" #从branchA拷贝出一个新分支branchB |
1 | svn merge branchAbranchB # 把对branchA的修改合并到分支branchB |
TortoiseSVN是windows下其中一个非常优秀的SVN客户端工具。通过使用它,我们可以可视化的管理我们的版本库。不过由于它只是一个客户端,所以它不能对版本库进行权限管理。
点击SVN Checkout,弹出检出提示框,在URL of repository输入框中输入服务器仓库地址,在Checkout directory输入框中输入本地工作拷贝的路径,点击确定,即可检出服务器上的配置库。
如果配置库在本地已有工作拷贝,则取得最新版本只是执行SVN Update即可,点击SVN Update,系统弹出更新提示框,点击确定,则把服务器是最新版本更新下来
选择要提交到服务器的目录,右键选择TortoiseSVN—-Import,系统弹出导入提示框,在URL of repository输入框中输入服务器仓库地址,在Import Message输入框中输入导入日志信息,点击确定,则文件导入到服务器仓库中。
如果有多个文件及文件夹要提交到服务器,我们可以先把这些要提交的文件加入到提交列表中,要执行提交操作,一次性把所有文件提交,如图,可以选择要提交的文件,然后点击执行提交(SVN Commit),即可把所有文件一次性提交到服务器上
有时你从档案库更新文件会有冲突。冲突产生于两人都修改文件的某一部分。解决冲突只能靠人而不是机器。当产生冲突时,你应该打开冲突的文件,查找以<<<<<<<开始的行。冲突部分被标记:
<<<<<<< filename
your changes
code merged from repository
>>>>>>> revision
Subversion为每个冲突文件产生三个附加文件:
filename.ext.mine
更新前的本地文件。
filename.ext.rOLDREV
你作改动的基础版本。
filename.ext.rNEWREV
更新时从档案库得到的最新版本。
使用快捷菜单的编辑冲突Edit Conflict命令来解决冲突。然后从快捷菜单中执行已解决Resolved命令,将改动送交到档案库。请注意,解决命令并不解决冲突,而仅仅是删除filename.ext.mineandfilename.ext.r*文件并允许你送交。
点击Check for Modifications,系统列表所以待更新的文件及文件夹的状态.
查看文件的分支,版本结构,可以点击Revision Graph,系统以图形化形式显示版本分支.
SVN支持文件改名,点击Rename,弹出文件名称输入框,输入新的文件名称,点击确定,再把修改提交,即可完成文件改名
SVN支持文件删除,而且操作简单,方便,选择要删除的文件,点击Delete,再把删除操作提交到服务器
选择待移动的文件和文件夹;按住右键拖动right-drag文件(夹)到跟踪拷贝内的新地方;松开左键;在弹出菜单中选择move files in Subversion to here
还原操作,如刚才对文件做了删除操作,现在把它还原回来,点击删除后,再点击提交,会出现如上的提示框,点击删除后,再点击Revert,即已撤销删除操作,如果这时候点击提交,则系统弹出提示框:没有文件被修改或增加,不能提交
当需要创建分支,点击Branch/Tag,在弹出的提示框中,输入分支文件名,输入日志信息,点击确定,分支创建成功,然后可查看文件的版本分支情况
文件创建分支后,你可以选择在主干工作,还是在分支工作,这时候你可以通过Switch来切换。
主干和分支的版本进行合并,在源和目的各输入文件的路径,版本号,点击确定。系统即对文件进行合并,如果存在冲突,请参考冲突解决。
把整个工作拷贝导出到本地目录下,导出的文件将不带svn文件标志,文件及文件夹没有绿色的”√”符号标志。
当服务器上的文件库目录已经改变,我们可以把工作拷贝重新定位,在To URL输入框中输入新的地址
大多数项目会有一些文件(夹)不需要版本控制,如编译产生的*.obj, *.lst,等。每次送交,TortoiseSVN提示那些文件不需要控制,挺烦的。这时候可以把这些文件加入忽略列表。
客户端修改用户密码:打开浏览器,在地址栏内输入http://192.168.1.250/cgi-bin/ChangePasswd,启动客户端修改用户密码的界面,输入正确的用户名,旧密码,新密码(注意密码的位数应该不小于6,尽量使用安全的密码),点击修改即可.
把自己工作拷贝所做的修改提交到版本库中,这样别人在获取最新版本(Update)的时候就可以看到你的修改了。
显示当前文件(夹)的所有修改历史。SVN支持文件以及文件夹独立的版本追溯。
查看当前版本库,这是TortoiseSVN查看版本库的入口,通过这个菜单项,我们就可以进入配置库的资源管理器,然后就可以对配置库的文件夹进行各种管理,相当于我们打开我的电脑进行文件管理一样。
查看当前项目或文件的修订历史图示。如果项目比较大型的话,一般会建多个分支,并且多个里程碑(稳定版本发布),通过这里,我们就可以看到项目的全貌。
如果当前工作拷贝和版本库上的有冲突,不能自动合并到一起,那么当你提交修改的时候,tortoisesvn就会提示你存在冲突,这时候你就可以通过这个菜单项来解决冲突。冲突的解决有两种,一种是保留某一份拷贝,例如使用配置库覆盖当前工作拷贝,或者反过来。还有一种是手动解决冲突,对于文本文件,可以使用tortoiseSVN自带的工具,它会列出存在冲突的地方,然后你就可以和提交者讨论怎么解决这个冲突。同时它也对Word有很好的支持
从版本库中获取某一个历史版本。这个功能主要是方便查看历史版本用,而不是回滚版本。注意:获取下来之后,对这个文件不建议进行任何操作。如果你做了修改,那么当你提交的时候SVN会提示你,当前版本已失效(即不是最新版本),无法提交,需要先update一下。这样你所做的修改也就白费了。
如果你对工作拷贝做了一些修改,但是你又不想要了,那么你可以使用这个选项把所做的修改撤销
如果当前工作拷贝有任何问题的话,可以使用这个选项进行修正。例如,有些文件原来是版本控制的,但是你没有通过tortoiseSVN就直接删除了,但是tortoiseSVN还是保留着原来的信息(每个文件夹下都有一个.svn的隐藏文件夹,存放着当前文件夹下所有文件夹的版本信息)所以这就会产生一些冲突。可以使用cleanup来清理一下。
如果你不想别人修改某个文件的话,那么你就可以把这个文件进行加锁,这样可以保证只有你对这个文件有修改权。除非你释放了锁,否则别人不可能提交任何修改到配置库中
Branch是分支的意思。例如当在设计一个东西的时候,不同的人有不同的实现,但是没有经过实践检验,谁也不想直接覆盖掉其他人的设计,所以可以引出不同的分支。将来如果需要,可以将这些分支进行合并。
tag是打标签的意思。通常当项目开发到一定程度,已经可以稳定运行的时候,可以对其打上一个标签,作为稳定版。将来可以方便的找到某个特定的版本(当然我们也可以使用版本号来查找,但是数字毕竟不方便)
SVN对于分支和标签都是采用类似Linux下硬链接的方式(同一个文件可以存在两个地方,删除一个不会影响另一个,所做修改会影响另一个),来管理文件的,而不是简单的复制一份文件的拷贝,所以不会有浪费存储空间的问题存在。
这个功能是方便我们部署用。当我们需要发布一个稳定版本时,就可以使用这个功能将整个工程导出到某个文件夹,新的文件夹将不会包含任何版本信息了。
当我们版本库发生转移的时候就需要用到这个功能了。例如我原先的版本库是建在U盘上的,现在转移到(复制整个配置库文件夹)开发服务器上,使用https代替文件系统的访问。因此就需要将原来的工作拷贝的目标版本库重新定位到开发服务器上。
创建补丁。如果管理员不想让任何人都随便提交修改,而是都要经过审核才能做出修改,那么其他人就可以通过创建补丁的方式,把修改信息(补丁文件)发送给管理员,管理员审核通过之后就可以使用apply patch提交这次修改了。
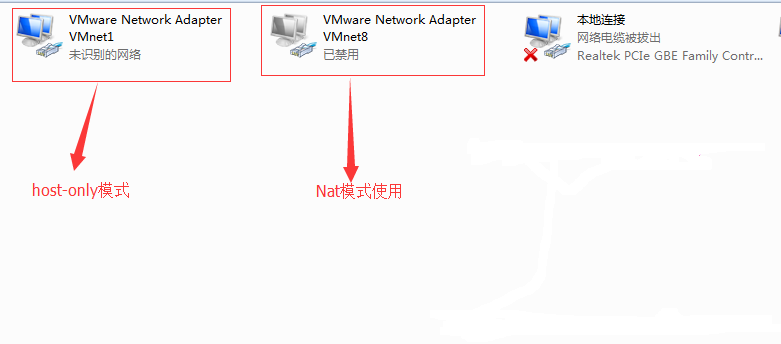
VMWare提供了三种工作模式,它们是bridged(桥接模式)、NAT(网络地址转换模式)和host-only(主机模式)。安装好虚拟机以后,在网络连接里面可以看到多了两块网卡。如下图
1 | 在这种模式下,VMWare虚拟出来的操作系统就像是局域网中的一台独立的主机,它可以访问网内任何一台机器。 |
架构图:
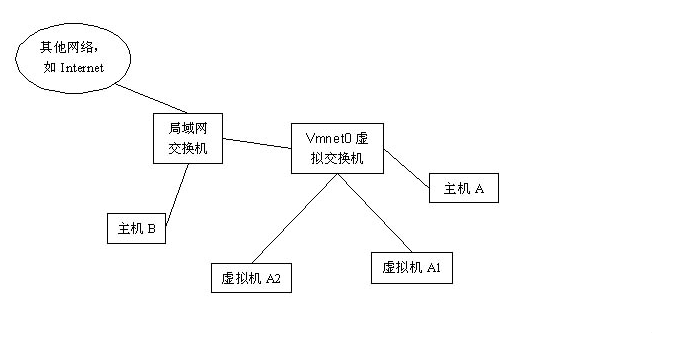
使用VMnet0虚拟交换机,此时虚拟机相当与网络上的一台独立计算机与主机一样,拥有一个独立的IP地址。使用桥接方式,A,A1,A2,B可互访
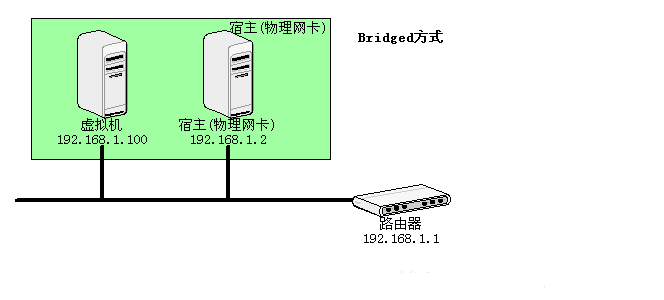
虚拟机就像一台真正的计算机一样,直接连接到实际的网络上,可以理解为与宿主机没有任何联系。
1 | 在某些特殊的网络调试环境中,要求将真实环境和虚拟环境隔离开,这时你就可采用host-only模式。在host-only模式中,所有的虚拟系统是可以相互通信的,但虚拟系统和真实的网络是被隔离开的。 |
架构图:
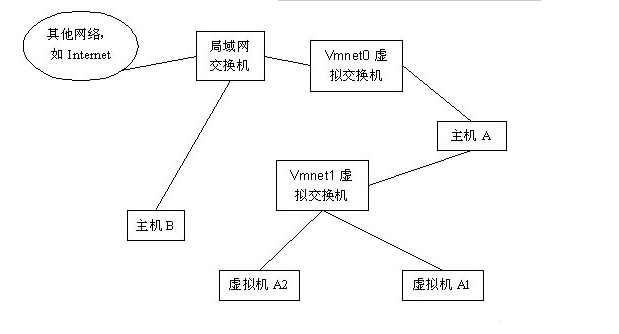
使用Vmnet1虚拟交换机,此时虚拟机只能与虚拟机、主机互访。也就是不能上Internet。使用Host方式,A,A1,A2可以互访,但A1,A2不能访问B,也不能被B访问。
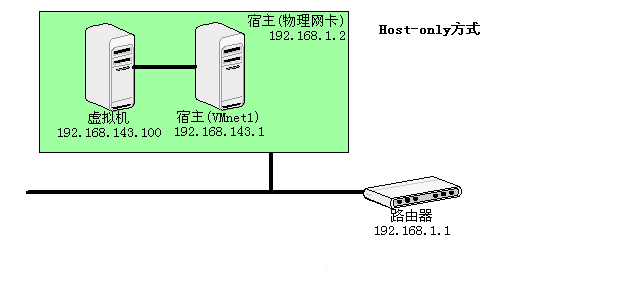
这种方式下,虚拟机的网卡连接到宿主的 VMnet1 上,但系统并不为虚拟机提供任何路由服务,因此虚拟机只能和宿主机进行通信,而不能连接到实际网络上。
1 | 使用NAT模式,就是让虚拟系统借助NAT(网络地址转换)功能,通过宿主机器所在的网络来访问公网。也就是说,使用NAT模式可以实现在虚拟 系统里访问互联网。NAT模式下的虚拟系统的TCP/IP配置信息是由VMnet8(NAT)虚拟网络的DHCP服务器提供的,无法进行手工修改,因此虚 拟系统也就无法和本局域网中的其他真实主机进行通讯。采用NAT模式最大的优势是虚拟系统接入互联网非常简单,你不需要进行任何其他的配置,只需要宿主机 器能访问互联网即可。 |
架构图:
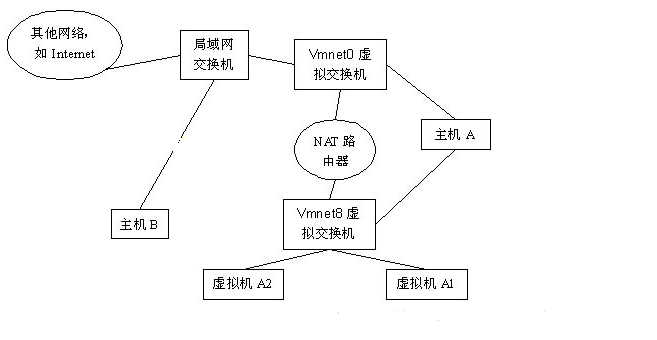
使用Vmnet8虚拟交换机,此时虚拟机可以通过主机单向网络上的其他工作站,其他工作站不能访问虚拟机。用NAT方式,A1,A2可以访问B,但B不可以访问A1,A2。但A,A1,A2可以互访。
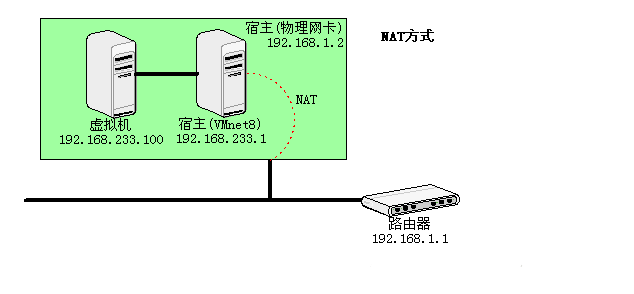
这种方式下,虚拟机的网卡连接到宿主的 VMnet8 上。此时系统的 VMWare NAT Service 服务就充当了路由器的作用,负责将虚拟机发到 VMnet8 的包进行地址转换之后发到实际的网络上,再将实际网络上返回的包进行地址转换后通过 VMnet8 发送给虚拟机。VMWare DHCP Service 负责为虚拟机提供 DHCP 服务。
vmx文件是虚拟机系统的配置文件,记录虚拟机的配置的,如内存、硬盘。
vmdk则是虚拟磁盘文件。
复制对应Virtual Machines的.vmx文件和所有的.vmdk文件到新电脑,VMware Workstation中打开虚拟机,选择.vmx文件即可
原因:
ssh服务未开启/苹果的安全限制
解决:
开启服务
sudo launchctl load -w /System/Library/LaunchDaemons/ssh.plist
查看ssh服务是否开启
sudo launchctl list |grep ssh
苹果的安全限制
sudo systemsetup -f -setremotelogin on
在安装Python3(>=3.3)时,Python的安装包实际上在系统中安装了一个启动器py.exe,默认放置在文件夹C:\Windows\下面。这个启动器允许我们指定使用Python2还是Python3来运行代码(当然前提是你已经成功安装了Python2和Python3)。
运行代码:
1 | py -2 hello.py #python2 |
如果你觉得参数 -2/-3 麻烦,由于 py.exe 这个启动器允许你在代码里面加入说明,指示这个文件是用python2还是3版本运行,可以在代码文件最前面加入一行说明
python2版本(编码说明可以放在第二行)
1 | #!python2 |
python3版本
1 | #!python3 |
这样就可以直接运行
1 | py hello.py #将自动转入相应版本1 |
当2和3同时存在Windows上时,他们对应的pip都叫pip.exe,所以不能直接使用 pip install 命令安装软件包,而是依靠py.exe来指定pip版本。
1 | py -2 -m pip install ***** #python2 |
按照环境变量的前后,如以 python 2 为 优先:
设置环境变量PATH为:
1 | C:\Python27;C:\Python27\Scripts;C:\Python36\Scripts\;C:\Python36\; |
pyenv是一个forked自ruby社区的简单、低调、遵循UNIX哲学的Python环境管理工具,用于安装和管理多个Python版本。它使开发人员能够快速访问更新版本的Python,并保持系统干净,避免不必要的包膨胀。它还提供了从 Python 的一个版本快速切换到另一个版本的能力,以及指定给定项目使用的Python版本并可以自动切换到该版本, 同时结合vitualenv插件可以方便的管理对应的包源
github:
https://github.com/pyenv/pyenv
https://github.com/pyenv-win/pyenv-win
安装依赖
1 | apt install -y make build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev xz-utils tk-dev libffi-dev liblzma-dev python-openssl git |
clone存储库
1 | git clone https://github.com/pyenv/pyenv.git ~/.pyenv |
配置环境
1 | 设置一些重要的环境变量并设置 pyenv 自动完成 |
验证安装
1 | 列出可用的 Python 版本 |
命令
参阅 pyenv help <command>
安装
1 | choco install pyenv-win |
命令
1 | pip install --upgrade pip |
1 | pip config list |
1 | pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ |
1 | 阿里云 |
1 | "(py -2/3 -m)pip" |
1 | 只需通过 == 操作符指定 |
1 | pip升级format问题: |
确保 Python 已经具备虚拟环境配置库:
1 | pip install virtualenv |
在某一文件夹下创建虚拟环境:
1 | virtualenv venv |
虚拟环境生效使用虚拟环境的二进制目录中的脚本来“激活”该环境。不同平台调用的脚本是不同的(须将 <venv> 替换为包含虚拟环境的目录路径)
| 平台 | Shell | 用于激活虚拟环境的命令 |
|---|---|---|
| POSIX | bash/zsh/git-bash | $ source |
| fish | $ source |
|
| csh/tcsh | $ source |
|
| PowerShell Core | $ |
|
| Windows | cmd.exe | C:> |
| PowerShell | PS C:> |
1 | 1. 变量命名总结: |
1 | """ |
1 | 1.是否以start开头:str.startswith('start') |
1 | os.sep:取代操作系统特定的路径分隔符 |
1 | AssertionError 断⾔语句(assert)失败 |
pyton连接数据库需要先安装pymysql模块:pip install pymysql
安装完成后导入pymysql模块:import pymysql
python连接数据库主要分五个步骤:
step1:连接数据库
step2:创建游标对象
step3:对数据库进行增删改查
step4:关闭游标
step5:关闭连接
1 | # 1. 连接数据库, |
1 | #首先导入所需要的模块 |
1 | #银行转账系统考虑因素主要包括: |
xlrd.biffh.XLRDError: Excel xlsx file; not supported
1 | 原因是最近xlrd更新到了2.0.1版本,只支持.xls文件。所以pandas.read_excel(‘xxx.xlsx’)会报错。 |
1 | import random |
1 | pip install paramiko |
1 | 第一步:导入paramiko |
example:
1 | import paramiko |
1 | import paramiko |
1 | from jsoncompare import jsoncompare as json_comp |
最好用虚拟环境,不加其他无关的依赖
1 | pip install pyinstaller |
favicon.ico在线制作:http://www.favicon-icon-generator.com/
1 | Pyinstaller -F -w -i mergepdf.ico mergepdf.py |
官方文档:https://pyinstaller.readthedocs.io/en/stable/usage.html
参数
| -h,–help | 查看该模块的帮助信息 |
|---|---|
| -F,-onefile | 产生单个的可执行文件 |
| -D,–onedir | 产生一个目录(包含多个文件)作为可执行程序 |
| -a,–ascii | 不包含 Unicode 字符集支持 |
| -d,–debug | 产生 debug 版本的可执行文件 |
| -w,–windowed,–noconsolc | 指定程序运行时不显示命令行窗口(仅对 Windows 有效) |
| -c,–nowindowed,–console | 指定使用命令行窗口运行程序(仅对 Windows 有效) |
| -o DIR,–out=DIR | 指定 spec 文件的生成目录。如果没有指定,则默认使用当前目录来生成 spec 文件 |
| -p DIR,–path=DIR | 设置 Python 导入模块的路径(和设置 PYTHONPATH 环境变量的作用相似)。也可使用路径分隔符(Windows 使用分号,Linux 使用冒号)来分隔多个路径 |
| -n NAME,–name=NAME | 指定项目(产生的 spec)名字。如果省略该选项,那么第一个脚本的主文件名将作为 spec 的名字 |
https://blog.csdn.net/weixin_42052836/article/details/82315118